

Le doline rappresentano una minaccia crescente per infrastrutture, terreni agricoli e risorse idriche, richiedendo metodi sempre più precisi e automatizzati per la loro individuazione. In questo contesto nasce SinkSAM-Net, un innovativo framework di segmentazione auto-supervisionata basato su conoscenza geotopografica, che integra dati RGB, stima di profondità da singola immagine (MDE) e il potente modello Segment Anything (SAM).
Questo approccio consente di rilevare doline in modo accurato ed efficiente, anche in aree estese e complesse, superando i limiti di tecniche tradizionali come LiDAR o DEM fotogrammetrici. Monitorare l’occorrenza e le caratteristiche delle doline del suolo è fondamentale per studiare le dinamiche delle aree soggette a questo fenomeno e mitigare i rischi ad esso correlati. Le doline si manifestano sulla superficie terrestre come depressioni, osservabili a occhio nudo o tramite piattaforme di telerilevamento (Kim et al., 2019). Tuttavia, l’individuazione automatica delle doline del suolo attraverso immagini da telerilevamento (RS) è ancora una sfida, finora affrontata da pochi ricercatori (Rahimi et al., 2024). Le difficoltà derivano dal fatto che le doline hanno forme irregolari, sono soggette a effetti di ombreggiamento interno ed esterno, possono essere mascherate dalla vegetazione e sono solitamente distribuite in modo sparso su ampie aree, rappresentando un tipico problema di dati sbilanciati (Bernatek-Jakiel e Poesen, 2018).
Per affrontare queste sfide, possono essere utilizzate informazioni topografiche ausiliarie per migliorare la segmentazione delle doline nelle immagini RS. Fonti di dati come il LiDAR (rilevamento e misurazione della luce) o i Modelli Digitali di Elevazione (DEM) fotogrammetrici (Pardo-Igúzquiza e Dowd, 2021; Arav et al., 2025) sono stati impiegati in diverse analisi topografiche. Tuttavia, i LiDAR aerotrasportati sono raramente usati ad alta risoluzione su vaste aree a causa dei costi estremamente elevati (Raj et al., 2020). I DEM fotogrammetrici possono presentare scarsa accuratezza nella rappresentazione del terreno, poiché spesso confondono vegetazione o strutture edilizie con la superficie del suolo. Sono inoltre sensibili alle condizioni di luce e ombre, che possono causare errori nei dati altimetrici. Rispetto ai DEM derivati da LiDAR, i modelli fotogrammetrici hanno solitamente una precisione verticale limitata. Inoltre, faticano a rappresentare terreni ripidi, poiché le coppie di immagini sovrapposte potrebbero non cogliere adeguatamente gli angoli acuti dei pendii. Problemi di corrispondenza stereo possono portare a lacune o distorsioni nel DEM finale (Uysal et al., 2015).
Come alternativa a queste due fonti topografiche, la stima di profondità monoculare (MDE), sviluppata di recente mediante tecniche di deep learning su immagini RGB singole, è diventata centrale nel campo della computer vision (Zhao et al., 2020). La MDE si è rivelata utile nella ricostruzione 3D e nella segmentazione di istanze target. Tuttavia, negli studi di telerilevamento, la MDE è ancora molto poco utilizzata (Miclea e Nedevschi, 2022), in particolare negli studi geomorfologici. Ciò è un peccato, poiché la MDE non richiede visioni multiple come riferimento, migliorando tempi ed efficienza del processo (Ming et al., 2021).
L’estrazione automatica delle doline si è basata su diverse variabili geomorfometriche, come pendenza dei versanti, curvatura e posizione topografica (Zhu et al., 2020). Il metodo “fill sinks” è stato applicato con successo in diversi studi (Pardo-Igúzquiza e Dowd, 2021; Hofierka et al., 2018), ma le caratteristiche estratte da questo approccio spesso soffrono di sovrastima e scarsa precisione nella definizione dei confini delle doline. Di conseguenza, le depressioni identificate attraverso dati topografici richiedono spesso una rifinitura, solitamente tramite post-processing e ispezione visiva delle immagini RGB da parte di operatori umani (Ferreira et al., 2023).
Oltre al calcolo deterministico geometrico, le informazioni topografiche sono state utilizzate anche per migliorare i modelli di segmentazione, come le Reti Neurali Convoluzionali (CNN) (Yuan et al., 2020). Diverse architetture encoder–decoder sono state impiegate nei compiti di segmentazione delle doline (Zhu et al., 2017), spesso usando combinazioni di DEM e immagini RGB come input.
Recentemente, i modelli fondativi zero-shot hanno guadagnato popolarità nei compiti di computer vision (Lüddecke e Ecker, 2022), offrendo una maggiore capacità di generalizzazione grazie all’apprendimento di concetti e relazioni di alto livello, invece che essere vincolati a etichette di classe predefinite durante l’addestramento (Liu et al., 2024). Il modello SAM (Segment Anything Model), basato su ViT (Vision Transformer), consente la segmentazione delle immagini con un intervento umano minimo, richiedendo solo un box o un punto come prompt per iniziare la segmentazione (Kirillov et al., 2023). Tuttavia, le doline condividono caratteristiche geometriche comuni che possono fungere da forti prior per generare pseudo-etichette con SAM, riducendo l’intervento umano durante l’addestramento (da Rocha Nunes de Castro et al., 2024). Finora, tutti gli studi pubblicati sulla segmentazione delle doline si basano su grandi quantità di immagini annotate manualmente, un processo costoso e dispendioso in termini di tempo, che ne limita la scalabilità nei grandi dataset RS (Jones, 2024).
Sebbene il SAM mostri potenziale come generatore di pseudo-etichette zero-shot tramite l’interazione con la geometria delle doline come prompt, affronta ancora notevoli sfide nelle applicazioni RS (Xiao et al., 2024). Inoltre, il SAM comporta un notevole carico computazionale a causa della sua architettura pesante e dipende ancora dai prompt per ottenere un’accurata segmentazione, anche dopo il fine-tuning (Ren et al., 2024). Di conseguenza, è necessario un approccio più avanzato, leggero e automatizzato, che sfrutti le capacità zero-shot del SAM per l’apprendimento auto-supervisionato, permettendo una segmentazione accurata delle doline.
In risposta a queste sfide, questo articolo propone un framework generale auto-supervisionato e guidato dalla conoscenza per la segmentazione delle doline, chiamato SinkSAM-Net. L’obiettivo è migliorare la segmentazione delle doline tramite un’architettura innovativa completamente automatica, auto-supervisionata, auto-correggente ed efficiente dal punto di vista computazionale. Sono stati definiti tre obiettivi operativi per raggiungere questo scopo:
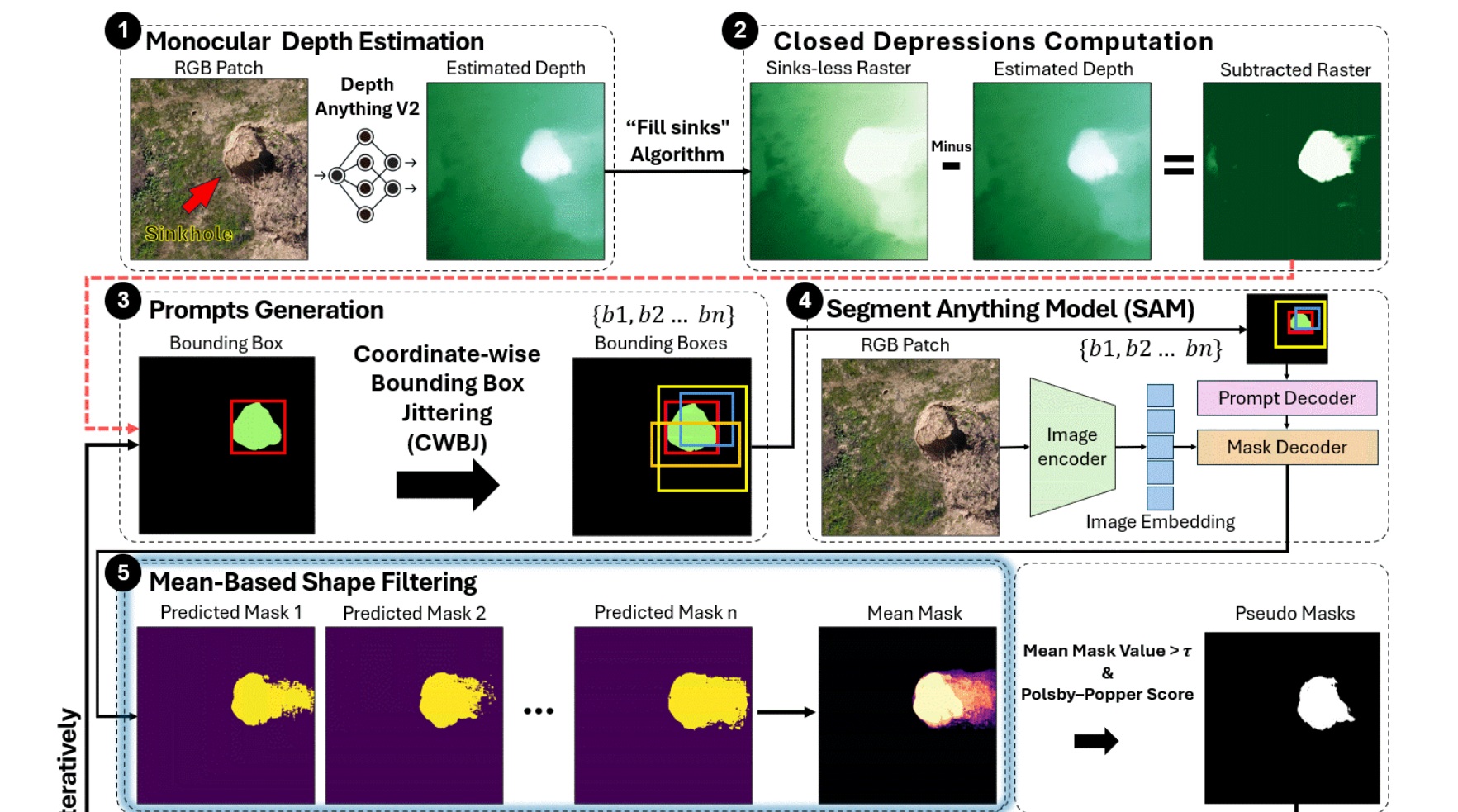
- Raffinare automaticamente i confini chiusi delle depressioni derivati dai DEM, utilizzando la segmentazione basata su prompt delle immagini RGB da drone, mediante un innovativo generatore di etichette basato su jittering delle bounding box tramite simulazioni Monte Carlo con SAM 2.1 in modalità zero-shot;
- Semplificare il processo basandosi esclusivamente su immagini RGB, integrando la stima di elevazione tramite Depth Anything V2 (DAV2) basata sul deep learning;
- Trasferire la conoscenza dal SAM (modello ricco di parametri) a un’architettura leggera di segmentazione semantica end-to-end priva di prompt, basata su EfficientNetV2-U-Net, con basso numero di parametri e requisiti computazionali minimi, per migliorarne l’applicabilità pratica.
Uno studio comparativo con dataset annotati manualmente è stato condotto per dimostrare l’efficacia del framework proposto. In ultima analisi, si auspica che SinkSAM-Net rappresenti una base per lo sviluppo di un modello fondativo per la segmentazione delle doline su larga scala e con capacità di generalizzazione.
I principali contributi dell’articolo alla segmentazione delle doline sono:
- SinkSAM-Net ha ottenuto un raffinamento a livello di pixel delle depressioni chiuse tradizionali derivate da DEM, integrando dati RGB con bounding box jittering coordinate-wise (CWBJ) e filtraggio basato sulla forma per generare pseudo-etichette di alta qualità.
- L’uso di prompt automatici derivati dalla stima di profondità monoculare (da una singola immagine RGB) ha superato i limiti e i bias dei DEM fotogrammetrici, rendendo possibile la mappatura delle doline senza ricorrere a costosi dati LiDAR. DAV2 si è dimostrato efficace come sostituto AI per i dati di elevazione
Fonte: ( ScienceDirect )
